Enterprise IT infrastructure increasingly requires storage systems capable of handling diverse data types simultaneously. Traditionally, organizations siloed their data environments. Block storage managed structured, high-performance application data, while file storage handled unstructured user data and shared directories. This strict separation creates inefficiencies in capacity planning, resource allocation, and administrative overhead.
Unified storage environments resolve these inefficiencies by consolidating block and file protocols into a single system. This convergence simplifies management and reduces hardware footprints. However, processing mixed workloads on a shared architecture presents specific technical challenges. Storage controllers must rapidly switch context between handling precise block-level inputs and hierarchical file-system requests without degrading performance.
Understanding how modern NAS Storage architectures process these divergent I/O profiles is critical for system architects. By examining the underlying mechanisms of unified storage, organizations can deploy infrastructure that meets stringent latency requirements while providing massive scalability.
The Convergence of Block and File Data
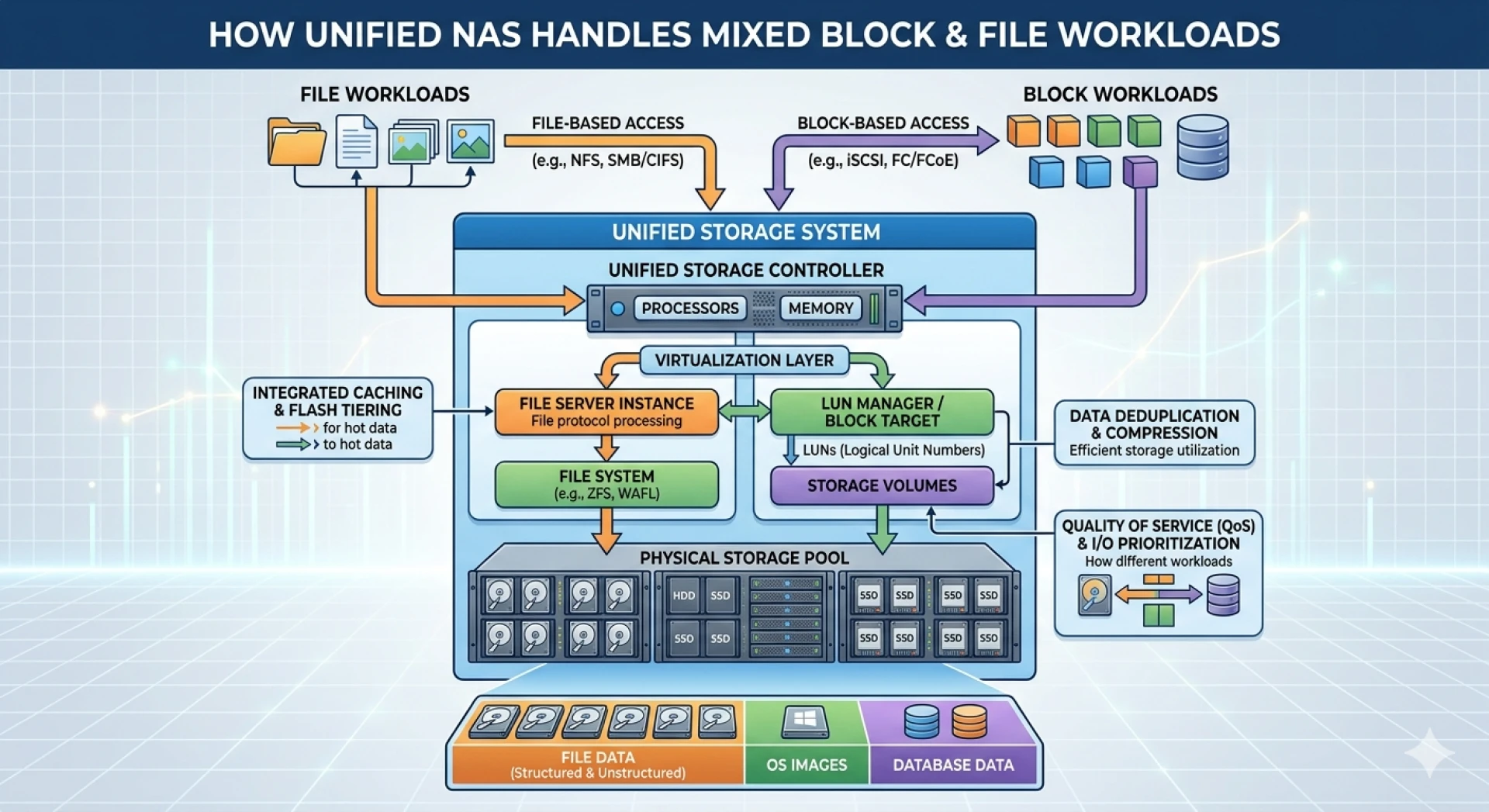
To comprehend unified storage, architects must first analyze how the system differentiates and processes incoming I/O requests. Block storage protocols, such as iSCSI or Fibre Channel, interact directly with the storage media. The operating system handles the file system layer, allowing for high-speed data transfers ideal for databases and virtual machines.
Conversely, NAS Storage utilizes file-based protocols like NFS or SMB. The storage system itself manages the file system, presenting shared folders over the network. This method is highly effective for collaborative environments and unstructured data repositories.
Unified storage architectures bridge this gap by utilizing a sophisticated operating system that virtualizes the underlying physical disks. This virtualized pool is then provisioned as either logical unit numbers (LUNs) for block access or file systems for NAS access. The storage controller dynamically allocates CPU and cache resources based on the specific protocol requirements of the incoming workload, ensuring that intensive block transactions do not starve file-based operations.
How Scale Out NAS Transforms Workload Management?
Traditional scale-up architectures eventually hit performance bottlenecks when controllers max out their processing capabilities. To handle aggressive mixed workloads, enterprises are adopting scale out nas architectures.
Distributed File Systems
A scale out nas architecture utilizes a distributed file system that spans multiple independent storage nodes. As capacity or performance requirements increase, administrators simply add more nodes to the cluster. The software automatically balances the data and incoming I/O requests across all available hardware.
This distribution is particularly beneficial for mixed workloads. By spreading the processing burden, a scale out prevents any single node from becoming overwhelmed by a sudden spike in block-level database queries or massive file-level data migrations.
Dynamic Resource Allocation
Advanced scale out systems employ machine learning algorithms to monitor I/O patterns in real-time. If the system detects a latency-sensitive block workload, it can automatically pin that data to high-speed flash storage. Simultaneously, colder file data can be dynamically tiered to high-capacity mechanical drives or cloud object storage. This automated tiering ensures optimal performance for critical applications while maintaining cost efficiency for archival data.
Integrating Cloud Infrastructure
Modern unified storage is rarely confined to on-premises hardware. Hybrid cloud deployments allow architects to extend their storage networks into public cloud environments, providing unprecedented flexibility.
When deploying workloads that require high IOPS and low latency in the cloud, administrators often utilize Azure disk storage. Azure disk storage provides managed, high-performance block storage volumes that attach directly to virtual machines.
Storage architects can integrate on-premises unified storage with cloud resources by utilizing software-defined storage or specialized replication protocols. This allows organizations to maintain file services locally via their NAS Storage, while replicating mission-critical block data to Azure disk storage for disaster recovery or cloud-bursting compute scenarios. The result is a seamless data fabric that spans local data centers and cloud platforms.
Optimizing the Storage Environment for the Future
Consolidating block and file data into a unified storage environment significantly streamlines IT operations. By leveraging intelligent controller software and dynamic caching, these architectures successfully process divergent I/O profiles without compromising application performance.
Organizations facing rapid data growth should evaluate scale out nas solutions to ensure their infrastructure can expand seamlessly. Furthermore, integrating public cloud resources ensures that the storage architecture remains resilient and adaptable. By systematically analyzing workload requirements and matching them to appropriate hardware and cloud solutions, IT leaders can build highly efficient, scalable, and robust data storage environments.









Sign in to leave a comment.